The human genome has 3 billion "letters". But for scientific research and in commercial tests only a small subset of genes is used. From half a million to few millions. Ancient DNA can have even less "letters". Sometimes few dozen thousands. Nevertheless even this small number require complex methods for comparison.
One method which is used by amateurs is the Gedmatch and G25 where the available genome is transformed into a row of numbers. Usually from 10 to 25 numbers. And those numbers are compared to each other. But as You can understand it's a very approximate way to do because the huge info is zipped into small number set. Despite this most of the time those methods give a good idea about the DNA. This is especially true for G25.
But academic papers do not rely on those amateur tools. Well they use the Admixture and PCA programs which are behind the Gedmatch and G25 but the they do not make conclusions based solely on those tools.
For making solid scientific conclusions they rely on more complex tools. One of them is the qpadm.
This is a very complex tool. As far as I know no one in this group have skills to use it. But thanks to Nareg Asatrian we have access to a person who can run the qpadm models. From my side I will add also some from my collection. Notice qpadm results are important because You can use them in an academic publication and create a solid reference. I will post qpadm results in the comments. In this texts I will mention only the p value and the proportion. A p value is a number between 0 to 1. It means how plausible is the model. If it is close to 1 it means a practical certitude. A number lower than 0.05 means improbable. Although in some papers You will see models with less than 0.05. Keep in mind that finding a plausible model with relatively high p value is very hard.
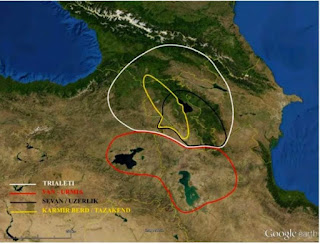
Let's start from simple things. Like comparing Yervanduni era Armenians from RoA ( 4 samples ) to modern average Armenians.
Well we have two models both have p value higher than 0.05. One of them is 0.17 the other 0.10. Both are made of different set of 3 samples. So the models are feasible.
Then we tried the Van Urartu samples to modern Armenians. Initially two attempts failed which was quite surprising given how close are those samples in G25 to modern Armenians. But when Lebanon Armenians were used the model worked quite well. P value 0.547. But the average and eastern Armenians require something else on top of Van Urartu, which we discussed a lot in this group.
Now we want to know what is that Van Urartu. It turns out that Van Urartu can be modeled as a 50% mixture of Lchashen culture and something like Dinkha tepe (NW Iran) or Syria Ebla EMBA. P value 0.68. Notice I have a thread in this group about the connection of Urartians to Dinkha tepe which is related to Khabur ware. Basically qpadm confirms this connection. Although it must be noted that this type of North Mesopotamian ancestry was present in. Sirnak (modern Hakkari/ historic Korduk) much earlier.